
8. Retrieval transmission spectra¶
8.1. Notebook setup¶
%load_ext autoreload
%autoreload 2
import glob as glob
import matplotlib as mpl
import matplotlib.patheffects as PathEffects
import matplotlib.pyplot as plt
import matplotlib.transforms as transforms
import numpy as np
import pandas as pd
import seaborn as sns
import bz2
import corner
import json
import pathlib
import pickle
import utils
import warnings
from astropy import constants as const
from astropy import units as uni
from astropy.io import ascii, fits
from astropy.time import Time
from mpl_toolkits.axes_grid1 import ImageGrid
# Default figure dimensions
FIG_WIDE = (11, 5)
FIG_LARGE = (8, 11)
# Figure style
sns.set(style="ticks", palette="colorblind", color_codes=True, context="talk")
params = utils.plot_params()
plt.rcParams.update(params)
8.2. Load¶
base_dir = "data/retrieval_tspec"
# Retrievals with lowest and highest log-evidences
fpaths_dict_extrema = {
"K (clear)": f"{base_dir}/HATP23_E1_NoHet_FitP0_NoClouds_NoHaze_NofitR0_K", # Worst
"TiO (clear)": f"{base_dir}/HATP23_E1_NoHet_FitP0_NoClouds_NoHaze_NofitR0_TiO", # Best
}
data_dict_extrema = {
model_name: {
"tspec": ascii.read(f"{model_dir}/retr_model.txt"),
"tspec_sampled": ascii.read(
f"{model_dir}/retr_model_sampled_Magellan_IMACS.txt"
),
"retrieval": utils.load_pickle(f"{model_dir}/retrieval.pkl"),
}
for (model_name, model_dir) in fpaths_dict_extrema.items()
}
# Additional retreivals to compare overall shape
fpaths_dict = {
"Na+K (clear)": f"{base_dir}/HATP23_E1_NoHet_FitP0_NoClouds_NoHaze_NofitR0_Na_K",
"Na+K (cloud)": f"{base_dir}/HATP23_E1_NoHet_FitP0_Clouds_NoHaze_NofitR0_Na_K",
"Na+K (haze)": f"{base_dir}/HATP23_E1_NoHet_FitP0_NoClouds_Haze_NofitR0_Na_K",
"Na+K (spot)": f"{base_dir}/HATP23_E1_Het_FitP0_NoClouds_NoHaze_NofitR0_Na_K",
}
data_dict = {
model_name: {
"tspec": ascii.read(f"{model_dir}/retr_model.txt"),
"tspec_sampled": ascii.read(
f"{model_dir}/retr_model_sampled_Magellan_IMACS.txt"
),
"retrieval": utils.load_pickle(f"{model_dir}/retrieval.pkl"),
}
for (model_name, model_dir) in fpaths_dict.items()
}
# Instrument data
instrument_dict = {
"Magellan_IMACS": {
"plot_kwargs": {
"c": "w",
"mec": "k",
"fmt": "o",
"ecolor": "k",
"label": "Magellan/IMACS",
"zorder": 10,
},
"data": ascii.read(f"{base_dir}/instrument/retr_Magellan_IMACS.txt"),
}
}
8.3. Plot¶
fig, ax = plt.subplots(figsize=FIG_WIDE)
# Sample models
colors = ["C0", "C1", "C2", "C4"]
for color, (model_name, model_dict) in zip(colors, data_dict.items()):
p = utils.plot_model(
ax,
model_dict,
model_kwargs={"lw": 2, "label": model_name},
fill_kwargs={"color": color, "alpha": 0.15},
sample_kwargs={"marker": "o"},
)
# Best and worst models
colors = ["darkgrey", "C8"]
for color, (model_name, model_dict) in zip(colors, data_dict_extrema.items()):
p = utils.plot_model(
ax,
model_dict,
model_kwargs={"lw": 4, "label": model_name},
fill_kwargs={"color": color, "alpha": 0.15},
sample_kwargs={"marker": "o"},
)
# Instruments
for (instrument_name, instrument_data) in instrument_dict.items():
instrument_name = instrument_name.replace("_", "/")
utils.plot_instrument(ax, instrument_data)
# Species
species = {
"Na I-D": 5892.9,
#'Hα':6564.6,
"K I_avg": 7682.0,
"Na I-8200_avg": 8189.0,
}
[
ax.axvline(wav / 10000, lw=0.5, ls="--", color="grey", zorder=0)
for name, wav in species.items()
]
# Save
ax.legend(loc=1, ncol=4, fontsize=11)
ax.set_xlim(0.5, 0.95)
ax.set_ylim(12_400, 15_000)
ax.set_xlabel(r"Wavelength $(\mu\mathrm{m})$")
ax.set_ylabel("Transit depth (ppm)")
fig.tight_layout()
fig.set_size_inches(FIG_WIDE)
#utils.savefig("../paper/figures/retrieval_tspec/retrieval_tspec.pdf")
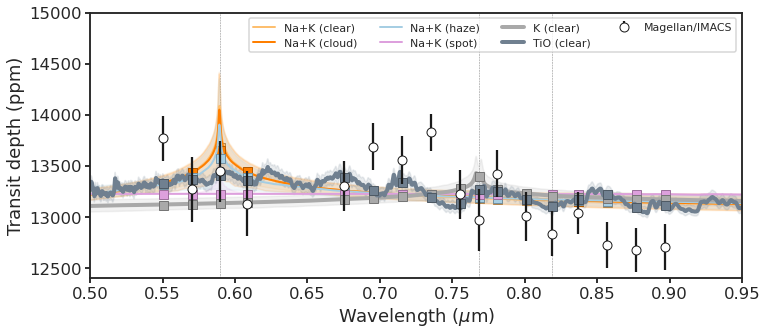
8.4. Table¶
dfs = []
for model_name, model_data in data_dict_extrema.items():
df_samples = pd.DataFrame(model_data["retrieval"]["samples"])
df_stats = utils.get_table_stats(df_samples, columns=[model_name])
dfs.append(df_stats)
for model_name, model_data in data_dict.items():
df_samples = pd.DataFrame(model_data["retrieval"]["samples"])
df_stats = utils.get_table_stats(df_samples, columns=[model_name])
dfs.append(df_stats)
dfs[0], dfs[1] = dfs[1], dfs[0] # Show TiO column first
dfs = pd.concat(dfs, axis=1).fillna("--")
dfs = dfs.rename(
index={
"logP0": r"\log P_0",
"logTiO": r"\log\text{ TiO}",
"logK": r"\log\text{ K}",
"logNa": r"\log\text{ Na}",
"logsigma_cloud": r"\log\sigma_\text{cloud}",
"loga": r"\log a",
"gamma": r"\gamma",
"Tocc": r"T_\text{star}",
"Thet": r"T_\text{spot}",
"Fhet": r"f_\text{spot}",
}
)
dfs#.to_clipboard()
| TiO (clear) | K (clear) | Na+K (clear) | Na+K (cloud) | Na+K (haze) | Na+K (spot) | |
|---|---|---|---|---|---|---|
| \log P_0 | 0.5^{+4}_{-4} | 3.4^{+2}_{-3} | 1.4^{+3}_{-3} | 0.8^{+3}_{-3} | 0.5^{+3}_{-3} | -1.3^{+4}_{-3} |
| T | 1751.1^{+783}_{-804} | 620.1^{+328}_{-209} | 1938.0^{+652}_{-779} | 1827.7^{+714}_{-950} | 1878.4^{+709}_{-973} | 1393.6^{+1043}_{-886} |
| \log\text{ TiO} | -7.1^{+4}_{-4} | -- | -- | -- | -- | -- |
| \log\text{ K} | -- | -2.6^{+2}_{-3} | -19.4^{+8}_{-7} | -18.7^{+8}_{-8} | -18.8^{+9}_{-7} | -19.0^{+8}_{-7} |
| \log\text{ Na} | -- | -- | -4.0^{+3}_{-3} | -3.9^{+3}_{-4} | -4.8^{+3}_{-10} | -15.5^{+9}_{-10} |
| \log\sigma_\text{cloud} | -- | -- | -- | -37.7^{+10}_{-8} | -- | -- |
| \log a | -- | -- | -- | -- | -11.0^{+14}_{-13} | -- |
| \gamma | -- | -- | -- | -- | -2.3^{+2}_{-1} | -- |
| T_\text{star} | -- | -- | -- | -- | -- | 5906.8^{+349}_{-327} |
| T_\text{spot} | -- | -- | -- | -- | -- | 2200.0^{+0}_{-0} |
| f_\text{spot} | -- | -- | -- | -- | -- | 0.0^{+0}_{-0} |